For the first time ever, AI models achieved prestigious gold-level scores at the International Mathematics Olympiad, one of the world’s premiere math competitions. Their success is an undeniable bragging right for the technology’s biggest supporters. But as it stands, Google and OpenAI’s most cutting-edge, experimental AI programs still can’t beat an extremely smart teenager.
It may seem ironic, but complex mathematics is still one of AI’s biggest hurdles. There are many analyses into why this remains such an issue, but generally speaking, it has to do with how the technology works. After receiving a prompt, AI like ChatGPT and Google Gemini break the words and letters down into “tokens,” then parse and predict an appropriate response. To an AI, an answer is just the most likely string of tokens. Humans, however, process them as words, sentences, and complete thoughts.
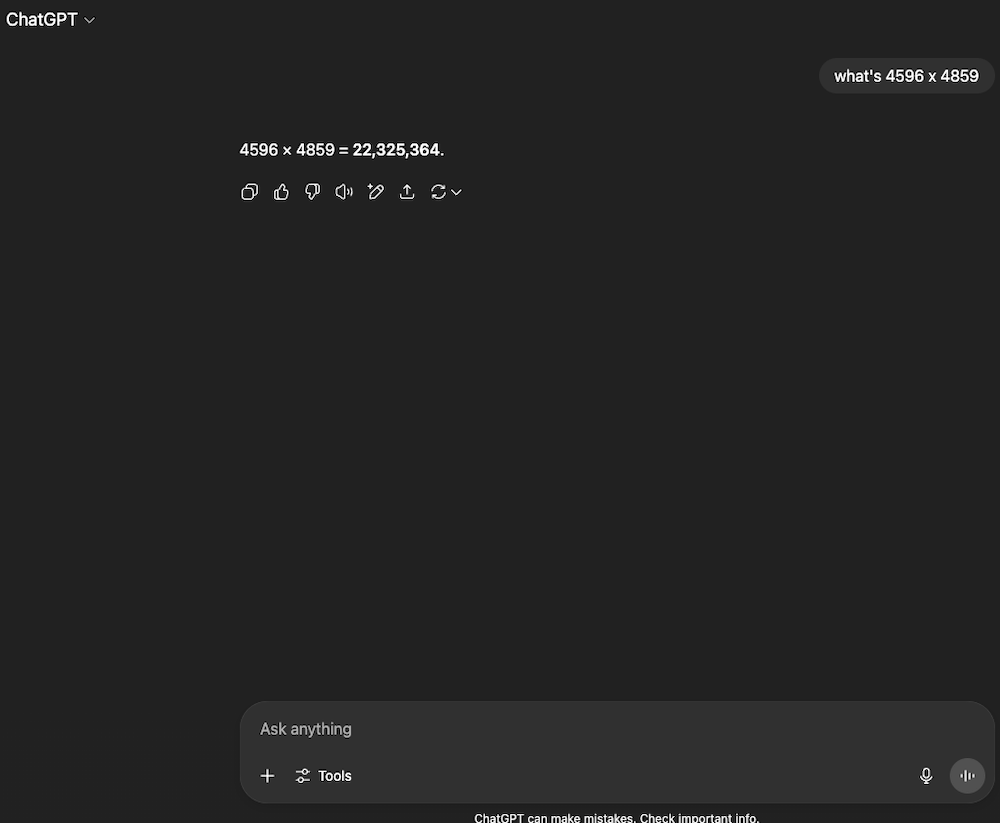
Given these parameters, AI doesn’t possess the “logic” capabilities required to handle complex mathematical prompts. This is largely because math prompts usually don’t have multiple possible answers—only a single, correct solution. Today, a pocket calculator will invariably give you the objectively true answer to multiplying 4596 by 4859 (22,331,964). Meanwhile, ChatGPT might still offer you an answer of 22,325,364:
Big improvements
Since 1959, the International Mathematical Olympiad (IMO) has served as one of the world’s premiere events for young—human—math whizzes. Many mathematicians would need longer than their allotted time to answer just one of the IMO’s problems—and most people wouldn’t be able to solve any of them.
Australia most recently hosted the 66th annual IMO competition in Queensland, where 641 teenagers from 112 countries met on July 15 to tackle six questions in under 4.5 hours. This time, however, they had some additional competition: a pair of experimental AI reasoning models from Google and OpenAI.
The bots fared well. Both companies have since announced that their programs scored high enough on this year’s IMO test to earn gold medals. Each AI managed to solve 5 of the 6 problems within the time limit, earning 35 out of the maximum 42 possible points. This year, only about 10 percent of human entrants received a gold-level score.
It marked a major improvement from Google’s last showing at IMO. In 2024, a version of its DeepMind reasoning AI reached a silver-medal score after solving four of six problems, although it required 2-3 days of computation instead of the 4.5-hour time limit. According to IMO president Gregor Dolinar, one of the most striking points of this year’s results wasn’t just the AI programs’ calculations, but the ways in which they explained their “thought” process to arrive at each answer.
“Their solutions were astonishing in many respects. IMO graders found them to be clear, precise and most of them easy to follow,” Dolinar said via Google’s announcement.
Big concerns
There’s at least one last IMO milestone for both companies: a perfect score. This year, five teens pulled off that accomplishment. And even if Google or OpenAI ties humans at the IMO in the coming years, the victory may still require context. As AFP noted, IMO organizers couldn’t confirm how much computing power was required by either AI model, or if there was any additional human oversight during the calculations.
And while AI’s latest technological leap forward is impressive, it still likely required disconcertingly massive amounts of energy and water. Companies like Google, OpenAI, and Microsoft are all investing heavily in data center projects to support their AI projects—all of which need power sources. In some cases, that may even include expanding the use of fossil fuels. Watchdogs previously estimated that at this rate, the AI industry may consume as much energy as Argentina, if not multiple nations combined. That’s a problem that AI—nor its makers—have yet to solve.






